是否曾經聽過查詢速度很慢時,需要加上些 index。
但你是否懷疑過,加入的 index 真的能夠有效的加速查詢嗎?是如何加速查詢的呢?
其實每一次的 SQL command 都會經過 SQL Planner,使用現有的資源,選擇最有利最有效的查詢。

接下來,將會介紹,
想要了解某 sql command 的執行效率,可以使用 explain。
如EXPLAIN select * from XXX_TABLE
以上指令單純分析,並無直接執行。
如果想要執行 sql command 並且輸出分析可以使用 EXPLAIN ANALYZE。EXPLAIN ANALYZE select * from XXX_TABLE
想當然,EXPLAIN 不只可以使用在 select 上,也可以使用在 update 與 delete,操作 rollback。
BEGIN;
EXPLAIN ANALYZE delete XXX_TABLE where id='OOO';
ROLLBACK
首先,我們可以先簡單執行一個 ExplainEXPLAIN ANALYZE select * from XXX_TABLE where id='OOO
獲得一個輸出。
Query Plan
______
Seq Scan on XXX_TABLE (cost=0.00..205.01 rows=1 width=35)
(actual time=1.945..1.946 rows=1 loops=1)
Planning time: 0.080ms
Execution time:1.965ms
(5 rows)
可以看到有兩行(cost=0.00..205.01 rows=1 width=35)與(actual time=1.945..1.946 rows=1 loops=1)
分別代表著估算與真實的狀況。
建議指南:
cost=0.00..205.01 第一個數字表示檢索第一行的成本,第二個數字表示檢索所有行的估計成本。rows=1 代表回傳的結果有幾個 recordswidth=35 是行的平均大小(以 kB 為單位)。actual time=1.945..1.946如同估算的 cost,不過這裡確確實實記載著真實的執行開始與結束時間。rows=1 代表回傳的結果有幾個 recordsloops=1 表示 seq scan 執行了一次,而檢索一行 rows=1 並花費了 1。946ms再來我們介紹一下,資料庫系統是如何找尋資料,有哪些方法。
順序掃描(地毯式搜索)
owl_conference=# EXPLAIN ANALYZE SELECT * FROM owl
WHERE owl.employer_name = 'Ulule';
QUERY PLAN
------------------------------------------------------------
Seq Scan on owl (cost=0.00..205.03 rows=1 width=35)
(actual time=1.904..1.904 rows=1 loops=1)
Filter: ((employer_name)::text = 'Ulule'::text)
Rows Removed by Filter: 10001
Planning time: 0.251 ms
Execution time: 1.956 ms
(5 rows)
看到一個Seq Scan順序掃描只是掃描整個表
然後使用Filter來將 Where owl.employer_name = 'Ulule';查詢出來
因此可以看到Rows Removed by Filter: 10001,
他真的看了整張表,然後將 employer_name 不等於 'Ulule' 取出,輸出 1 筆記錄
就如同看了整本字典,將你要查的那個字取出,耗費非常多不需要的時間
索引掃描
讓我們嘗試 employer_name 在之前查詢中使用的列上添加索引。CREATE INDEX ON owl (employer_name);
創建索引後,如果我們運行相同的查詢,它會突然開始使用索引
owl_conference=# EXPLAIN ANALYZE SELECT * FROM owl
WHERE employer_name='Ulule';
QUERY PLAN
-------------------------------------------------------------------------------------------
Index Scan using owl_idx on owl (cost=0.29..8.30 rows=1 width=35)
(actual time=2.399..2.400 rows=1 loops=1)
Index Cond: ((employer_name)::text = 'Ulule'::text)
Planning time: 0.111 ms
Execution time: 0.065 ms
索引掃描探索 B 樹並遍歷葉子以檢索匹配的行。
可以看到Index Scan 掃描了 index 表,
看到Index Cond在該 index tree 中找到符合條件的 node,rows=1最終輸出一筆 record
索引掃描就撈出
如果索引上的 node value 就是我們想要的值呢?是否可以直接做輸出?
尤其是 Index Organized Table,
他們查詢完了 Secondary Index,還要再次查 Clustered Index,實在累人。
Heap Organized Table 差距會小一點,因為他 index 後面就是直接指向 records pointer。
因此能直接撈出 index node value 即可就不需要再次查 Clustered Index。
explain select id from XXX_TABLE where id='OOO'
QUERY PLAN
------------------------------------
Index Only Scan using owl_idx on XXX_TABLE (cost=0.00...4.31 rows=1 width=4)
Index Cond: (id='OOO')
(2 rows)
如果希望能順帶帶出一兩個 col 來呢?可以使用INCLUDE clauseCREATE INDEX idx_include on XXX_TABLE(id) INCLUDE(name)
explain select name from XXX_TABLE where id='OOO'
QUERY PLAN
------------------------------------
Index Only Scan using owl_idx on XXX_TABLE (cost=0.00...4.31 rows=1 width=4)
Index Cond: (id='OOO')
(2 rows)
這樣就完全使用了Index Only Scan了,
不過 index 的硬碟使用空間也會隨之增大,畢竟 Index 上又多了一個 key 要存了。
索引掃描+bitmap
看到 Heap Scan,可以大膽顧名思義的猜測,
該不會是 Scan Heap Organized Table 的 Heap Table?
不能說全錯,但有些地方需要了解,請聽我娓娓道來。
剛剛我們雖然加上了 index 了,
但剛剛上面的案例都只輸出一筆紀錄rows=1,但如果我的 Query 需要 n 筆紀錄呢?
我們可以先分析一下剛剛Index Scan做了哪些事情。
就這三個步驟。
假設有 n 筆 records 呢?
那麼不就需要跑這三個步驟 n 次在 index tree 與 heap table 中來回跑?
有哪些可以優化?
其實我們可以改進一下步驟 2,3
第二步驟改成: 將符合資料的 pointer 所使用的 heap page,存入一個 map 結構中
第三步驟改成: 輸出 map 中的 pointer,進入 heap table 一次性的抓出所有 records
這麼一來,就算有 n 筆 records,也只需要跑一次這三個步驟了,
我們稱為 Bitmap Heap Scan。
至於第二步驟為什麼使用 bitmap 結構呢?
map 結構存了 key,value 那麼是怎麼存的呢?
看到右邊的框框了嗎?
這裡 key 使用 index value,value 使用二進位來表示 record 的位置,當使用兩個 index 時,bit 運算方便又快速。
來看範例你會更加明白。
owl_conference=# EXPLAIN ANALYZE SELECT * FROM owl
WHERE owl.employer_name = 'Hogwarts';
QUERY PLAN
------------------------------------
Bitmap Heap Scan on owl (cost=47.78..152.78 rows=2000 width=35)
(actual time=12.424..17.496 rows=2000 loops=1)
Recheck Cond: ((employer_name)::text = 'Hogwarts'::text)
Heap Blocks: exact=79
-> Bitmap Index Scan on owl_idx (cost=0.00..47.28 rows=2000 width=0)
(actual time=12.331..12.331 rows=2000 loops=1)
Index Cond: ((employer_name)::text = 'Hogwarts'::text)
Planning time: 0.117 ms
Execution time: 17.702 ms
(7 rows)
可以看到因為知道會有多筆 record,需要多個 map 結構來暫存多筆Heap Page,_特別注意!!存的是 page,不是 records _
所以採用 Bitmap Heap Scan,下面便列出是如何搜尋的。
Bitmap Index Scan on owl_idx,
就如同Index Scan on owl_idx一樣,使用 index tree 搜尋,
然後再使用 map(Bitmap)存下 page,Index Cond,和上個Index Scan的Index Cond一樣的意思,在該 index tree 中找到符合條件的 node。
那麼個別的Index Scan,就會各自有自己的Bitmap,
所以,有時會有BitMapAnd這句,將那些各自的Bitmap做 And 運算取出交集
(如果 where 下 or,當然就是取出聯集,變成BitMapOr),
再來一個值得探討的地方Recheck Cond,我們既然已經有了Index Cond,
為什麼還要再次做Recheck Cond?
剛剛提到了 Bitmap 結構存在 memory 中,當 Query 出很多資料時,
可能遇到一些問題。
所以,這裡發生了一點變化,如果資料非常多。
本來的 bitmap 會由直接存 records pointer,
變成 heap page 的 pointer,由於變成了 heap page 的 pointer,所以根本不知道整張 heap page 中,有哪些是我們真實想要的 records,這時就要將撈出來的 records,做Recheck Cond確定資料為我們想要的。
了解了單表查詢的方式了,想必大家也想了解兩表 join 時會是什麼樣的狀況呢?SELECT * FROM owl JOIN job ON (job.id = owl.job_id)
這裡我們稱 owl 為主表,job 為後面加入的,稱為副表。
暴力 join。
在選不到好的解法下,最簡單又暴力的暴力解,絕對是一個卍解,
但想當然爾,也犧牲了一些效能。
我們來看一下一個簡單的範例。
owl_conference=# EXPLAIN ANALYZE SELECT * FROM owl JOIN job ON (job.id = owl.job_id)
WHERE job.id < 3;
QUERY PLAN
------------------------------------------------------------------------------------
Nested Loop (cost=0.00..481.17 rows=2858 width=56)
(actual time=0.021..12.661 rows=9002 loops=1)
Join Filter: (owl.job_id = job.id)
Rows Removed by Join Filter: 11002
-> Seq Scan on owl (cost=0.00..180.02 rows=10002 width=35)
(actual time=0.011..1.875 rows=10002 loops=1)
-> Materialize (cost=0.00..1.10 rows=2 width=21)
(actual time=0.000..0.000 rows=2 loops=10002)
-> Seq Scan on job (cost=0.00..1.09 rows=2 width=21)
(actual time=0.006..0.007 rows=2 loops=1)
Filter: (id < 3)
Rows Removed by Filter: 5
Planning time: 0.386 ms
Execution time: 13.324 ms
(10 rows)
再用線條來呈現時間的花費。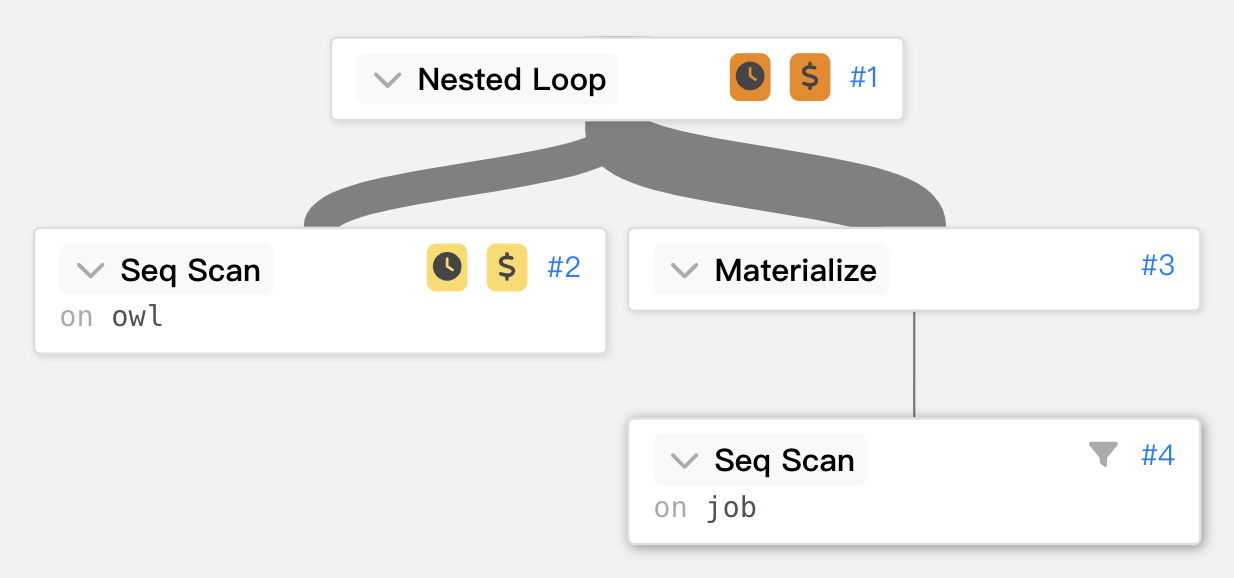
可以先從第二個階層開始看。Seq Scan on owl,代表直接掃整張表,sql 會將主表(SELECT * FROM owl)做一次掃表,共有 10002 筆資料。
再來就剩下另外一張被 join 的表了,
可以看到Materialize子層有Seq Scan on job,我們先看子層Seq Scan on job就是直接掃整張 job table。
Materialize,Materialize類似創建一個 virtual table 的概念,
將 query 出的結果暫存到一張表中,實際上視為一個表格,
然後Seq Scan on job得出了 2 rows,一直交付給每個 owl 上的每筆 records,loops=10002共跑了 10002 次,每次給出 2 筆 records,共 20004 筆 records
寫成程式大概是這樣。
const jobList = Job.objects.all(); // length= 2
const materialize = jobList;
const owlList = Owl.objects.all(); // length= 10002
for (owl in owlList.length) {
owl.tempJobs = materialize; // fetch snapshot 10002次
owl.job = owl.tempJobs.filter((job) => job.id !== owl.job_id);
}
不過明明是找 owl.job_id=job.i,怎麼最後是 owl.job_id=全部的 job,
因此更上層再使用Join Filter: (owl.job_id = job.id),
將多餘的 10002 筆移除,然後有些 owl 可能是失業的,也將那 1000 筆移除,共移除 11002 筆。
Hash Table join。
上面的 Nested loops 不分青紅皂白地就把 jobs 直接套上了,最後在做 filter 將多餘的移除。
那如果在 join 時,直接選取到目標的 job 不就更快了。
這裡先使用 Hash table 將 job 存入 table 中,然後讓主表直接做 join。
owl_conference=# EXPLAIN ANALYZE SELECT * FROM owl JOIN job ON (job.id = owl.job_id)
WHERE job.id > 3;
QUERY PLAN
------------------------------------------------------------------------------------
Hash Join (cost=1.15..290.12 rows=7144 width=56)
(actual time=0.143..4.790 rows=799 loops=1)
Hash Cond: (owl.job_id = job.id)
-> Seq Scan on owl (cost=0.00..180.02 rows=10002 width=35)
(actual time=0.032..2.258 rows=10002 loops=1)
-> Hash (cost=1.09..1.09 rows=5 width=21)
(actual time=0.082..0.082 rows=4 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Seq Scan on job (cost=0.00..1.09 rows=5 width=21)
(actual time=0.020..0.024 rows=4 loops=1)
Filter: (id > 3)
Rows Removed by Filter: 3
Planning time: 0.501 ms
Execution time: 4.927 ms
(10 rows)
再用線條來呈現時間的花費。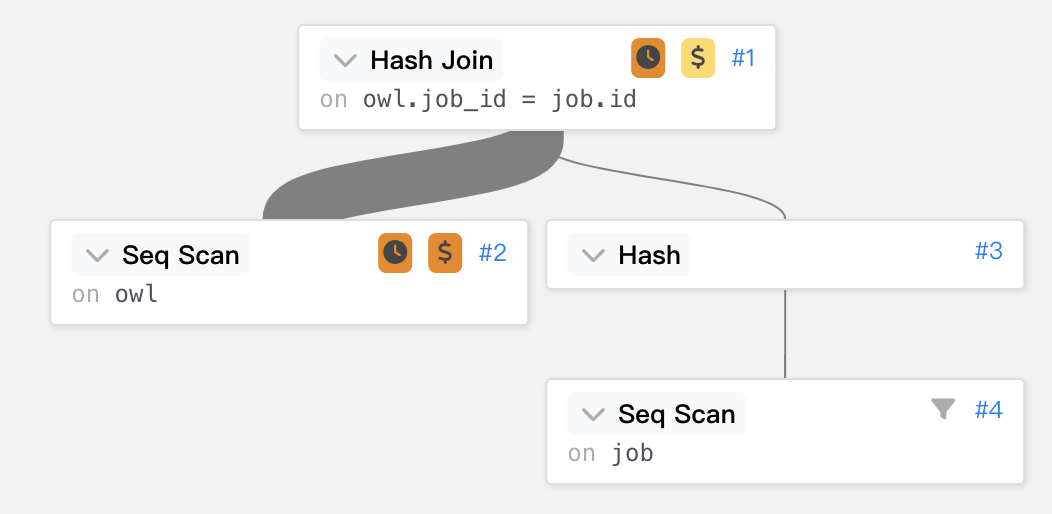
一樣的Seq Scan on owl直接掃整張主表。
再來就是這裡的特別介紹的Hash,
子層一樣是Seq Scan on job,不過這裡將結果使用 hash table 存起來。Buckets: 1024 Batches: 1 Memory Usage: 9kB代表該表有 1024 rows,並且該 hash table 使用了 9kb。
最後 owl 表經過 hash function 查找 hash table,取出對應的 job。
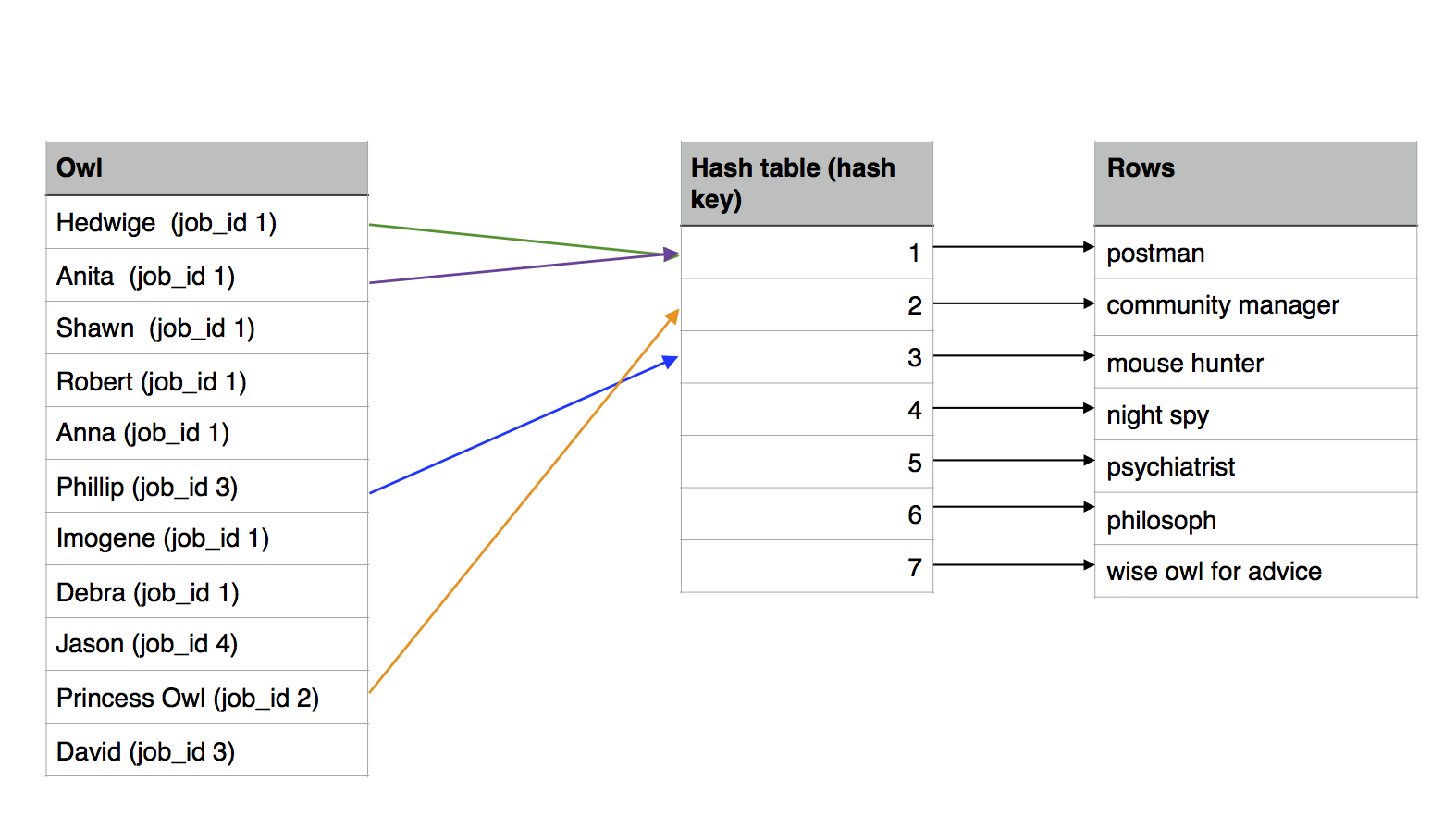
寫成程式大概是這樣
const jobList = Job.objects.all(); // length= 2
const jobHashTable = {};
for (job in jobList) {
jobHashTable[job.id] = job;
}
const owlList = Owl.objects.all(); // length= 10002
for (owl in owlList.length) {
owl.job = jobHashTable[owl.job_id]; //直接對應上,就不用在做filter了
}
既然感覺用起來比 nest loop 效率還高,為什麼還使用 nest loop?
nest loop join 小小表 ,hash table join 小表,那麼大表 join 就必定要使用 merge join 了,因為大表無法一次性的直接仔入到 memory 之中,因此需要分批次的做 join。
owl_conference=# EXPLAIN ANALYZE SELECT * FROM letters JOIN human ON (receiver_id = human.id)
ORDER BY letters.receiver_id;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------
Merge Join (cost=55576.25..62868.63 rows=413861 width=51)
(actual time=447.653..924.305 rows=413861 loops=1)
Merge Cond: (human.id = letters.receiver_id)
-> Sort (cost=895.22..920.25 rows=10010 width=23)
(actual time=4.770..7.747 rows=10001 loops=1)
Sort Key: human.id
Sort Method: quicksort Memory: 1167kB
-> Seq Scan on human (cost=0.00..230.10 rows=10010 width=23)
(actual time=0.008..1.777 rows=10010 loops=1)
-> Materialize (cost=54680.83..56750.14 rows=413861 width=24)
(actual time=442.856..765.233 rows=413861 loops=1)
-> Sort (cost=54680.83..55715.48 rows=413861 width=24)
(actual time=442.793..687.048 rows=413861 loops=1)
Sort Key: letters.receiver_id
Sort Method: external merge Disk: 15304kB
-> Seq Scan on letters (cost=0.00..7582.61 rows=413861 width=24)
(actual time=0.015..69.756 rows=413861 loops=1)
Planning time: 0.587 ms
Execution time: 982.440 ms
(13 rows)
再用線條來呈現時間的花費。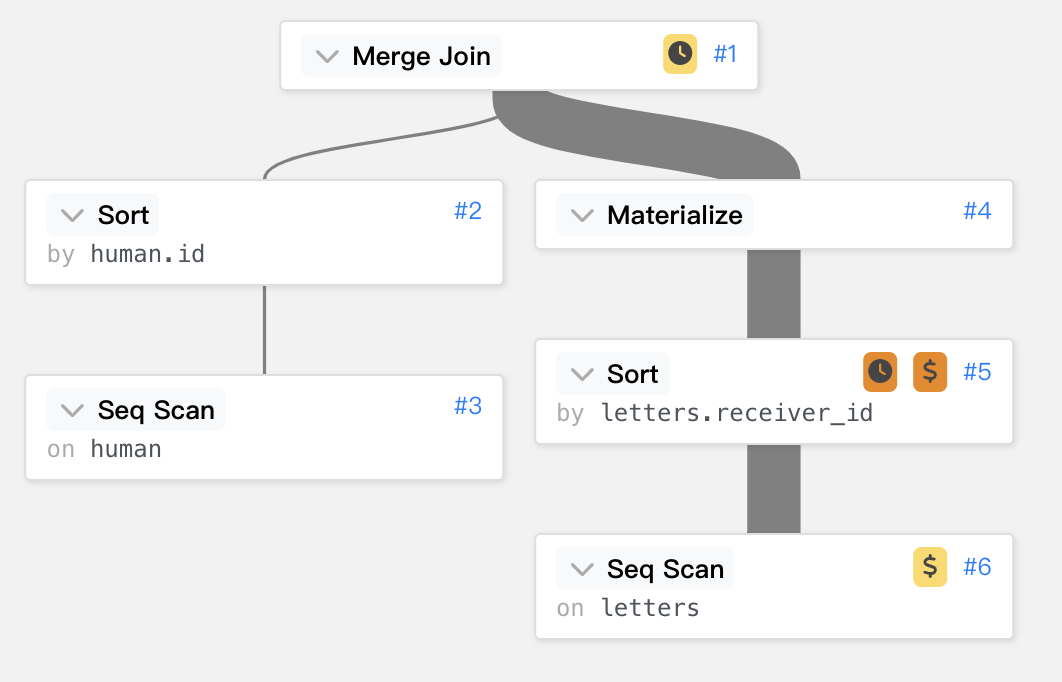
若以 Materialize 作為一刀切,可以看到他們主副兩表是Seq Scan完之後,再做 sort,
兩表的 sort 分別採用不同 sort 方法,使用 memory 還是 Disk 也有分別,
稍後會再額外介紹 sort,先讓大家了解這裡的運作。
主表依照 fk 做排序,附表依照 pk 做排序,將兩表排序好後,Merge Join就有點類似對對碰了概念,可以看到下圖,
兩表的最上方都是要 merge job_id=1 的 records,再來是 job_id=2 的以此類推。
就如同下圖動畫般,因為兩者的資料都是已經 sort 過了,可以很快速的做出對對碰。
假設我將主表的 fk 與副表 pk 事先排好呢?
我們可以利用 index 的特性將其 key 做好 sort。CREATE INDEX ON letters(receiver_id);
然後再做 merge join。
owl_conference=# EXPLAIN ANALYZE SELECT * FROM letters JOIN human ON (receiver_id = human.id)
ORDER BY letters.receiver_id;
QUERY PLAN
----------------------------------------------------------------------------------------------
Merge Join (cost=0.71..31442.44 rows=413861 width=51)
(actual time=0.033..648.119 rows=413861 loops=1)
Merge Cond: (human.id = letters.receiver_id)
-> Index Scan using humain_pkey on human (cost=0.29..1715.43 rows=10010 width=23)
(actual time=0.005..4.766 rows=10001 loops=1)
-> Index Scan using letters_receiver_id_idx on letters (cost=0.42..24530.28 rows=413861 width=24)
(actual time=0.024..502.212 rows=413861 loops=1)
Planning time: 0.626 ms
Execution time: 691.338 ms
(6 rows)
再用線條來呈現時間的花費。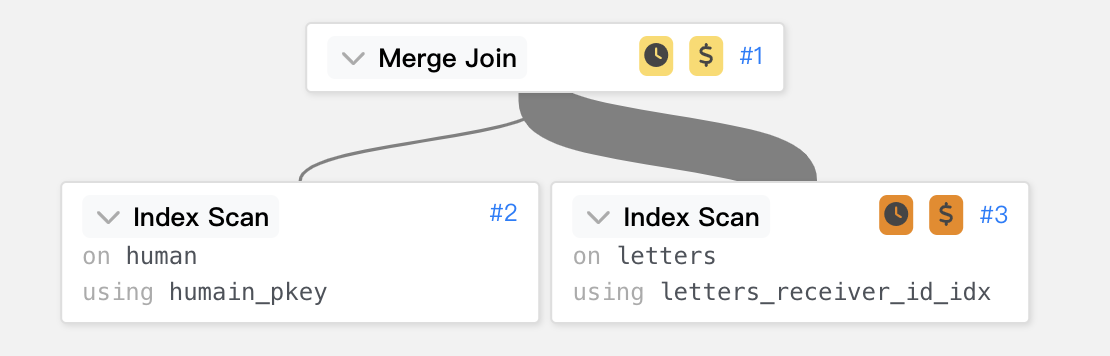
執行時間由 982.440 ms 降到了 691.338 ms ,主要就是少了 sort。
雖然少了 sort 的時間,但是將較大的副表做 scan 仍然是花上許多時間的,
所以,除非必要,真的不建議做大表的 join 喔,建議重新思考一下是否真的有這個必要做這個查詢。
排序,剛剛我們提到了 merge join 需要事先使用到 sort alg,
那麼什麼情況下該使用什麼樣的 sort alg,該使用 memory 還是 disk,
這都是可以細細品味的,這裡不是介紹各類演算法,有興趣的可以而外去研就。
我們將大致的介紹 Sort 的使用與 limit 與 offset。
dbms 之中,存在著許許多多的 sort,quicksort,heap sort ,merge sort ...,
Query Optimizer 將會自動選擇最有利的 sort 做處理。
owl_conference=# EXPLAIN ANALYZE SELECT * FROM human ORDER BY last_name;
QUERY PLAN
------------------------------------------------------------------------
Sort (cost=894.39..919.39 rows=10000 width=23)
(actual time=247.262..251.324 rows=10010 loops=1)
Sort Key: last_name
Sort Method: quicksort Memory: 1167kB
-> Seq Scan on human (cost=0.00..230.00 rows=10000 width=23)
(actual time=0.008..1.350 rows=10010 loops=1)
Planning time: 0.070 ms
Execution time: 252.504 ms
(6 rows)
再用線條來呈現時間的花費。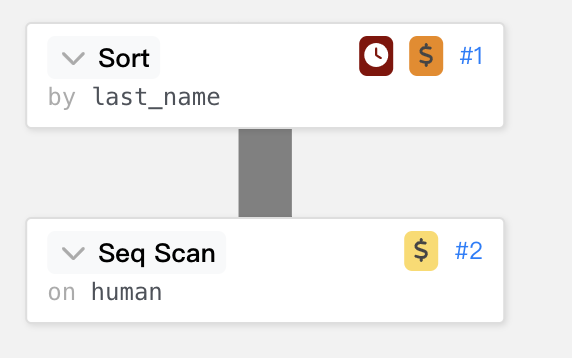
主要看到Sort Method這裡採用 quick sort,Memory使用了 1167kb 的 memory。
當使用到 limit 時,指的就是 Top-N,有點類似剪枝法的概念,
只要看到一點不符合條件的,就直接看都不用看的丟,因此可以減少不少的記憶體使用量。
owl_conference=# EXPLAIN ANALYZE SELECT * FROM human
ORDER BY last_name LIMIT 3;
QUERY PLAN
---------------------------------------------------------------------------------
Limit (cost=359.25..359.26 rows=3 width=23)
(actual time=17.726..17.727 rows=3 loops=1)
-> Sort (cost=359.25..384.25 rows=10000 width=23)
(actual time=17.725..17.726 rows=3 loops=1)
Sort Key: last_name
Sort Method: top-N heapsort Memory: 25kB
-> Seq Scan on human
(cost=0.00..230.00 rows=10000 width=23)
(actual time=0.054..3.186 rows=10010 loops=1)
Planning time: 0.271 ms
Execution time: 17.775 ms
(7 rows)
再用線條來呈現時間的花費。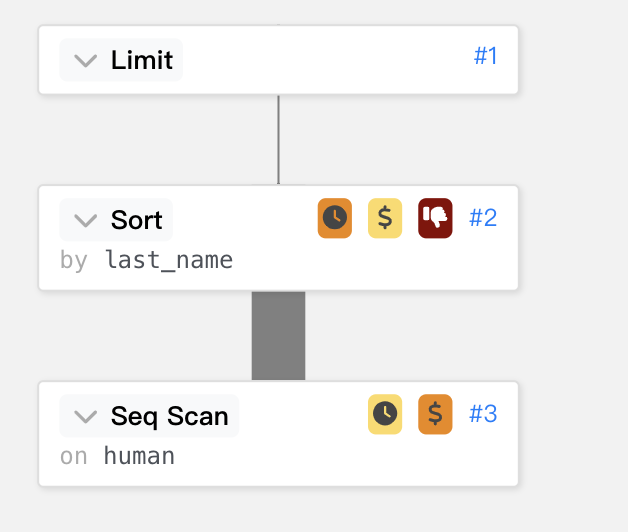
這裡的Sort Method改用了top-N heapsort,
memory 就從剛剛的 1167kB 下降到 25kB,並且縮短不少執行時間 252.504 ms 下降到 17.775 ms。top-N heapsort其實就是一個 Max/Min heap,
並且限定 node 數為 n,其餘超過條件的都會拋棄,符合條件的就會取代舊的。
CREATE INDEX ON human (last_name);
owl_conference=# EXPLAIN ANALYZE SELECT * FROM human
ORDER BY last_name LIMIT 3;
QUERY PLAN
-----------------------------------------------------------------
Limit (cost=0.29..0.54 rows=3 width=23)
(actual time=0.086..0.090 rows=3 loops=1)
-> Index Scan using human_last_name_idx on human
(cost=0.29..838.42 rows=10010 width=23)
(actual time=0.086..0.089 rows=3 loops=1)
Planning time: 0.336 ms
Execution time: 0.105 ms
(4 rows)
再用線條來呈現時間的花費。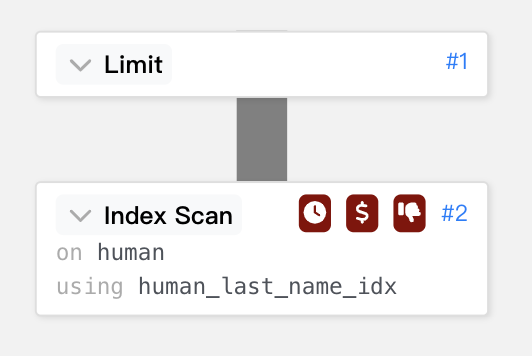
基本上只需要 Index Scan 後做 limit 即,因為 Index Scan 本來就是按造順序的 tree。


 iThome鐵人賽
iThome鐵人賽
{kind=link}